

Kings and Queens in AI
Exploring the emergent phenomenon of word analogies in Large Language Models

Imagine you’re solving a simple analogy puzzle: "Man is to Woman as King is to...?" If "Queen" sprang to mind, congratulations—you’ve just tapped into one of the most curious and inspiring phenomena in modern artificial intelligence. But here’s the twist: machines can solve this puzzle too. In fact, Large Language Models (LLMs) not only understand this analogy but do so in a way that reveals something fascinating about how AI grasps language and meaning.

Once I stumbled upon this research insight, I ask myself: How is it that LLMs, trained on massive datasets with no explicit knowledge of human relationships, can perform this kind of reasoning? The answer lies in the world of word embeddings and their linear structures. It’s a concept that reshapes how I think about machine intelligence and its surprising ability to "understand" the world. The fascinating aspect is that these large language models are not explicitly trained to understand these relationships, but that this is an emerging phenomenon.
What Are Word Embeddings?
At its core, a word embedding is a way to turn words into numbers—more specifically, vectors. If you’ve heard the phrase "computers only understand numbers," this is how words become those numbers.
In a word embedding system, each word is represented as a point in a high-dimensional space (think of it as plotting words on a graph, but with far more dimensions than we can visualize). It is estimated that LLMs have anywhere between 300-1000 dimensions (interestingly, we don’t exactly know how many dimensions are in an LLM). Words with similar meanings, like "king" and "queen," end up close together in this space, while words with different meanings, like "dog" and "banana," are far apart, because they have far less in common.
But here’s where things get wild: the relationships between words aren't random. Even though in the initial stages of training an LLM all the weights are set to random values, through its training process these weights become aligned to the semantic meaning of the language we feed it with. Now, imagine that you would measure the distance from "man" to "woman" in this space. It actually turns out that line is similar in direction and length to the line from "king" to "queen."
By the way, if you want to get an understanding, or simply play around with the visualization of such a word embedding, this project lets you visualize and explore embeddings. The image below shows
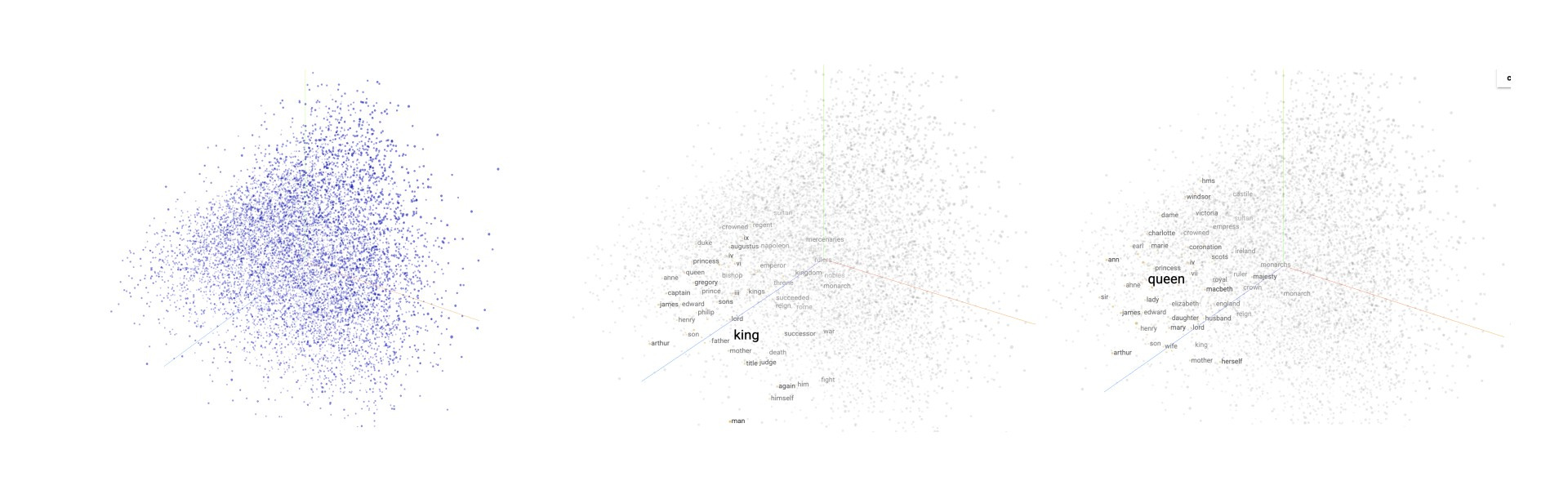
Large Language Models embed different type of relationships, ranging from geographical (e.g., capitals), socio-cultural (e.g., gender, nationality, currency), grammatical (adjective, plural, tense) and semantic (opposite, comparative, superlative).
What happens inside these AI models
The reason LLMs "know" that king - man + woman = queen is rooted in how they’re trained. These models learn from vast amounts of text, identifying patterns in how words co-occur. Over time, they develop a "spatial map" where concepts with similar relationships align along consistent directions.
Training: Models learn word embeddings by predicting which words are likely to appear near each other in a sentence. If "king" frequently appears in contexts similar to "queen" the model links them.
Conceptual Directions: During training, relationships like gender (man → woman, king → queen) or royalty (king → prince, queen → princess) manifest as consistent directions in that high-dimensional space. This happens not because the model "knows" about gender or royalty, but because it’s statistically embedded in the text it’s trained on.
Linear Algebra in Language: The magic happens when simple vector arithmetic works. If you subtract the vector for "man" from "king" and add the vector for "woman," you end up close to the position of "queen." Somehow the model has learned that the concept that you are looking for is “gender”.
What I find fascinating is that this is an emergent phenomenon. LLMs are not explicitly trained to handle analogies. No one tells these models that it should somehow embed the concept of gender as a direction in its high-dimensional space.
Modern LLMs have even more complex embeddings.
Earlier models produced "static" embeddings, meaning the same word always has the same vector. However, the modern LLMs use a different structure that better encapsulates the contextual meaning of a word. That allows modern LLMs to deal better with multiple meanings of a word and the position of words in a sentence. For example, the vector for "bank" in "river bank" differs from "bank" in "bank account." This is called contextualized embeddings.
Contextual embeddings are more dynamic, but they still show traces of the linear analogy structure. For example, even in more complex models, certain semantic directions—like gender, or profession—remain consistent. However, since the embeddings change with context, it’s harder to achieve the clean analogy results seen in static models. There is a great in-depth video (How might LLMs store facts) from 3Blue1Brown that also explores this topic.
The process of contextually adjusting embeddings layer-by-layer makes the analogy "king - man + woman = queen" more distributed across the model's internal layers. Research shows that certain layers in an LLM capture specific semantic properties better than others. This could mean that "conceptual hubs" emerge at different depths in the model.
This mirrors how humans interpret language contextually. For instance, the semantic meaning of words like "doctor" or "nurse" can shift subtly depending on gendered assumptions in a sentence, even though these roles are not inherently tied to gender. Consider these examples: "The doctor said she would review the results." vs "The doctor said he would review the results." or "The chairman called a meeting." whereas its uncommon to say "The chairwoman called a meeting."
In all these cases, meaning isn’t fixed—it’s negotiated through context. Early layers might identify "royalty" or "gender," while deeper layers synthesize these properties into a coherent output ("queen"). This layered, context-driven process reflects how both humans and models navigate semantic ambiguity.
The Broader Implications of Linear Analogies
The discovery that "king - man + woman = queen" works isn’t just a fun parlor trick. It’s an interesting insight into how LLMs conceptualize meaning.
Language Understanding: This analogy mechanism reveals that LLMs have internalized some "understanding" of human concepts. While not true comprehension, the ability to model relationships in this way is a significant milestone for machine intelligence.
Bias in AI: If "king - man + woman = queen" works, then so does "programmer - man + woman". Unfortunately, older embeddings often returned "homemaker" instead of "programmer," highlighting how societal biases present in training data are mirrored in embeddings. With the newer generations of models these type of biases are typically reduced and less prominent.
Explainability and Transparency: Knowing that LLMs rely on consistent "conceptual directions" makes it easier to understand and interpret their outputs. If we can identify the "gender axis" or "profession axis" in an embedding space, we can debug and improve models more effectively.
Measuring Model Intelligence: Some researchers propose that the richness of linear analogies in a model’s embeddings could be a proxy for the model’s capacity for abstraction. If a model can generalize the "X is to Y as A is to ?" structure across many concepts, it might signal a deeper cognitive ability.
Conclusion
I find that the idea that "king - man + woman = queen" holds true in AI is one of the most fascinating how LLMs ‘understand’ human language. It’s a reminder that human concepts can be captured, almost accidentally, by machines trained on raw data.
These linear analogies reveal how LLMs structure knowledge, understand context, and model relationships. They’re a glimpse into the cognitive "skeleton" of AI models—the internal scaffolding that allows them to recognize patterns, reason abstractly, and yes, solve analogy puzzles.
As we continue to explore the capabilities of AI, the simple elegance of a linear analogy reminds us that some of the most simple concepts may reveal inspiring complexities in LLMs.
Like kings and queens on a chessboard, the moves are simple—but the strategy is endlessly deep. (Yes, that sentence was generated by AI)
References
Mikolov, T., Chen, K., Corrado, G., & Dean, J. (2013). Efficient estimation of word representations in vector space.
ChatGPT, Claude and DeepSeek have been used to write parts of this article. The final review and editing is done by the author.